This is the second article about using PostgreSQL as a queue. The previous article can be read here.
The Background
Previously, we’ve explained that the remit is similar to that of Twitter; there are millions of users sending (let’s face it; utterly pointless) messages spaffed from their brains (loosely) into a data structure and on to an endpoint.
In this article we’ll explain how to start extracting some real performance from the loading mechanism.
The problem
In our system, the messages are arriving one at a time. A record arrives and we insert it reaching just over 12,000 records per second in our Rust API.
But inserting a single message into the database is wasteful. Bulk-loading data into a database - punching in 1000’s of records in a single insert - is far and way a much more efficient method. This is the key to performance gain.
The competition
Raising the Earth’s temperature by 0.1°C by asking various AI’s for Twitter’s peak load performance, they seemed think that Twitter’s peak load was just over 10,000 records per second. Here’s CoPilot’s opinion.
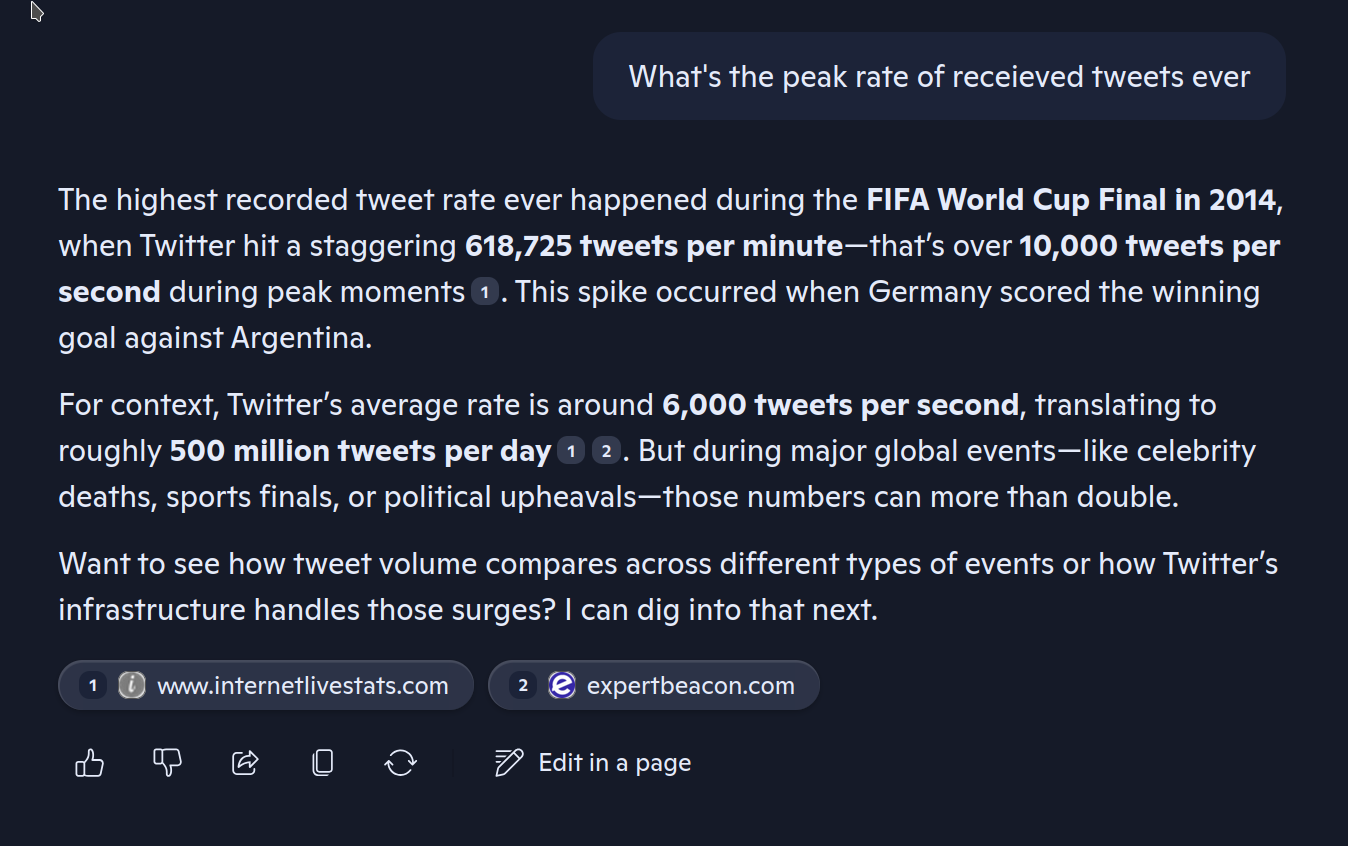
We’d like to comfortably beat this. The data we’re loading is millions of Tweets downloaded from Tweet archives from when they use to be open. Since then, we’ve modified the data, but it still full of the same sort of vapid nonsense.
The solution
In a tipping rain gauge, water collects in a bucket until it’s full. When full it tips out the contents and resets, ready to receive more. Adapting this to software, our API listens for incoming records, and having receieved 10,000 messages, tips our bucket over and delivers a single large insert into the database.
The software’s configurable so that the number of records that tip our bucket* can be altered to suit. It also has a timeout for bucket disgorgement. We might receive 9,999 records, insufficient records to cause a bucket emptying event and the bucket would remain partially filled and left in limbo, so if the timer reaches it’s threshold, we push the records in anyway and reset the bucket.
if record_number == 10_000 OR timeout >= 1_000 milliseconds {
insert_records_into_database(bucket);
bucket = [];
timeout = 0;
}
* Not a euphemism.
Is this a “time-based waterfall cascade proxy”?
Yeah, no, but yeah - sort of. The previous article suggested that something performing this function would be more distributed; a round-robin load balancer, but in this test, there’s no load-balancing, just the waterfally stuff.
Any good?
Yes. We’re seeing a significant improvement in performance. The final column shows the performance of the “waterfall” (WF) method. That’s an improvement of 4x over our previous loading performance and 5x faster than peak Twitter load.

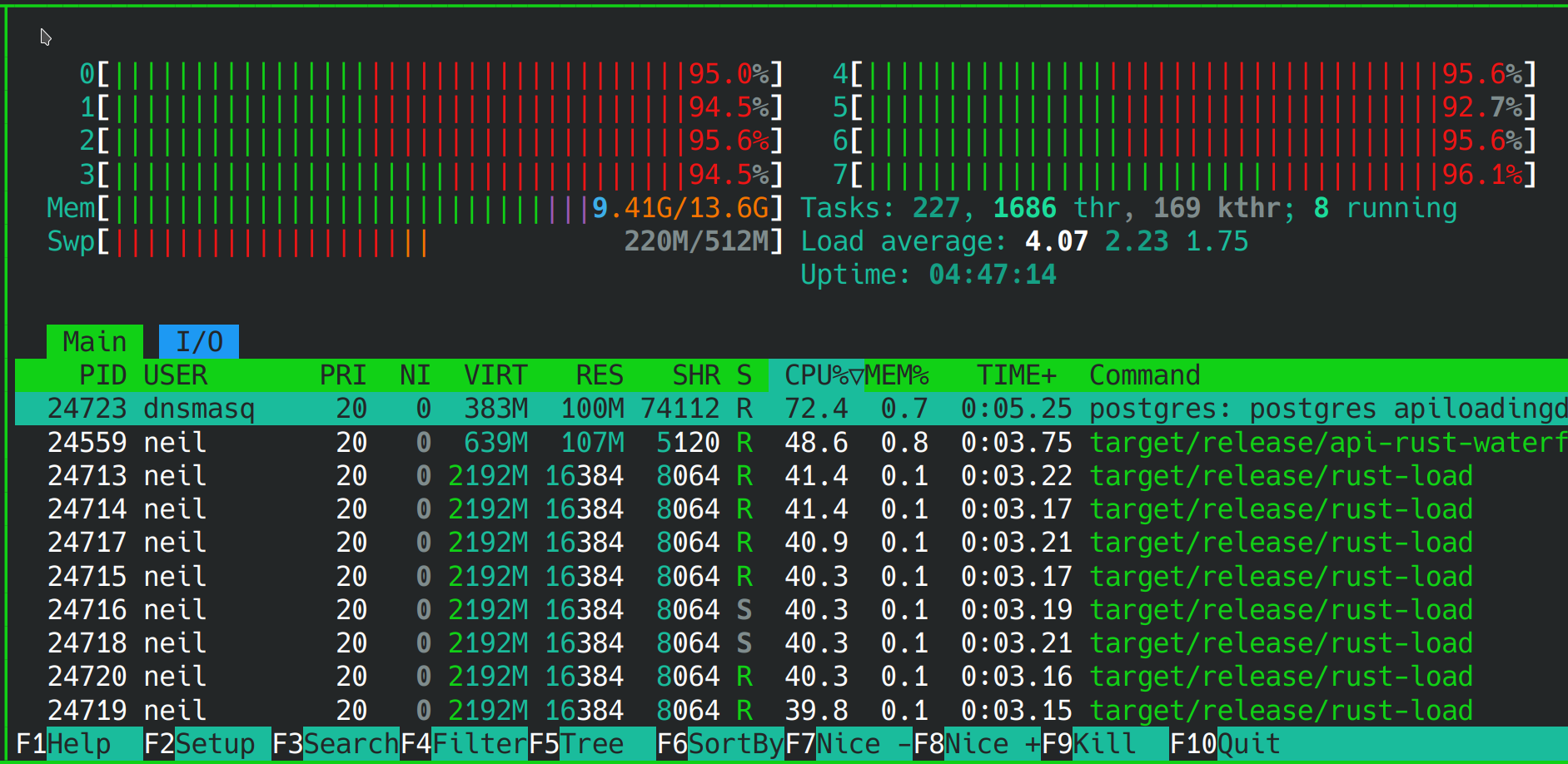
Busy?
Here you can see that the system’s very, very busy whilst it’s reading, decompressing, loading, transforming and inserting millions of records in PostgreSQL.
Is that it?
We’ve prototyped something that runs 5x faster on an old PC than peak Twitter and you ask if that’s it? Well, no, it isn’t. There are a couple more things that we want to investigate; power consumption per record loaded and HTTP overheads. The Rust-WF-HTTP column name’s a clue there.
These findings will be coming to this blog very soon.